

ChatGPT users have the option to scrap the web crawler by adding a “disallow” command to a standard file on the server…
Artificial intelligence firm OpenAI has launched “GPTBot” – its new web crawling tool it says could potentially be used to improve future ChatGPT models.
“Web pages crawled with the GPTBot user agent may potentially be used to improve future models,” OpenAI said in a new blog post, adding it could improve accuracy and expand the capabilities of future iterations.
A web crawler, sometimes called a web spider, is a type of bot that indexes the content of websites across the internet. Search engines like Google and Bing use them in order for the websites to show up in search results.
OpenAI said the web crawler will collect publicly available data from the world wide web, but will filter out sources that require paywalled content, or is known to gather personally identifiable information, or has text that violates its policies.
Breaking 🚨
OpenAI just launched GPTBot, a web crawler designed to automatically scrape data from the entire internet.
This data will be used to train future AI models like GPT-4 and GPT-5!
GPTBot ensures that sources violating privacy and those behind paywalls are excluded. pic.twitter.com/oR3kY4buaU
— Shubham Saboo (@Saboo_Shubham_) August 7, 2023
It should be noted that website owners can deny the web crawler by adding a “disallow” command to a standard file on the server.
Become Bulletproof Online Today With ZERO RISK!
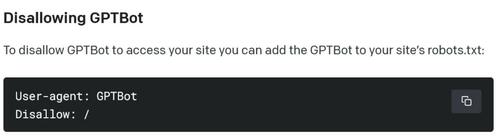 Instructions to “disallow” GPTBot for ChatGPT users. Source: OpenAI
Instructions to “disallow” GPTBot for ChatGPT users. Source: OpenAI
The new crawler comes three weeks after the firm filed a trademark application for “GPT-5,” the anticipated successor to the current GPT-4 model.
The application was filed at the United States Patent and Trademark Office on July 18, and covers the use of the term “GPT-5,” which includes software for AI-based human speech and text, converting audio into text and voice and speech recognition.
OpenAI has filed a trademark application for:
“GPT-5”
which includes “software for”:
“the artificial production of human speech and text”
“conversion of audio data files into text”
"voice and speech recognition"
"machine-learning based language and speech processing"
— YK aka CS Dojo 📺🐦 (@ykdojo) August 1, 2023
However, observers may not want to hold their breath for the next iteration of ChatGPT just yet. In June, OpenAI’s founder and CEO Sam Altman said the firm is “nowhere close” to beginning training GPT-5, explaining that several safety audits need to be conducted prior to starting.
Meanwhile, concerns have been raised over OpenAI’s data-collecting tactics of late, particularly revolving around copyright and consent.
Japan’s privacy watchdog issued a warning to OpenAI about collecting sensitive data without permission in June, while Italy temporarily banned the use of ChatGPT after alleging it breached various European Union privacy laws in April.
In late June, a class action was filed against OpenAI by 16 plaintiffs alleging the AI firm to have accessed private information from ChatGPT user interactions.
If these allegations are proven to be accurate, OpenAI — and Microsoft, who was named as a defendant — will be in breach of the Computer Fraud and Abuse Act, a law with a precedent for web-scraping cases.
Source: CoinTelegraph via ZeroHedge
Brayden Lindrea is an Australian-based freelance technical writer and journalist. He is most interested in how blockchain technology and cryptocurrencies will disrupt the traditional financial system.
Become a Patron!
Or support us at SubscribeStar
Donate cryptocurrency HERE
Subscribe to Activist Post for truth, peace, and freedom news. Follow us on SoMee, Telegram, HIVE, Flote, Minds, MeWe, Twitter, Gab, and What Really Happened.
Provide, Protect and Profit from what s coming! Get a free issue of Counter Markets today.
Be the first to comment on "OpenAI Launches Web-Crawler “GPTBot” Amid Plans For “GPT-5”"